发现没有,上周五DeepSeek V4发布后不到48小时,人们甚至还没来得及用它跑完一个完整项目,官方就甩出了另一枚炸弹。
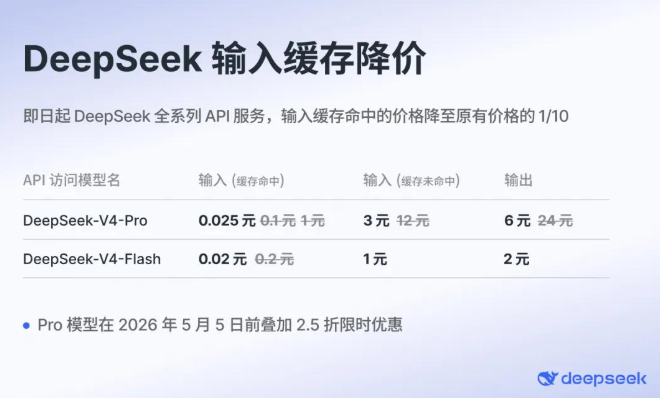
Pro版本API价格限时2.5折,优惠期持续到5月5日。紧接着,Pro和Flash的输入缓存命中价格一步到位,打到原价的十分之一。
第一反应是困惑。
3月以来,无论海外的OpenAI、Anthropic,还是国内的智谱、阿里、腾讯,AI产品与“降价”二字彻底绝缘。模型越做越大,API价格水涨船高,跑分结果一路往上,用户对着账单无话可说。行业在短短一个月内形成了惊人的默契:AI就该越来越贵,想体验到更好的智能,就得付更高的价格。而DeepSeek V4 Pro的价格已经逼近国内AI产品的下限,Flash版本比旧模型还便宜。此时继续降价,逻辑上无法解释。
第二反应是震惊。
输入缓存命中价格降到0.025元,在智能体时代说“接近免费”没有夸张成分。而且缓存命中的降价是永久的,不是限时活动。一个自然的质疑随之而来:这是不是文字游戏?必须缓存命中才能享受这个价格,实际使用中命中率能有多少?实测结果给出了答案:不是噱头,是真的便宜。
当国内外同行还在为几块钱的定价调整反复权衡时,DeepSeek直接把价格表里的小数点往左挪了一位。开发者眼里,这是慈善。竞争对手眼里,这是价格战。但两者都没有触及本质。
这是在清场。是一场早已分出胜负的成本斩杀。
DeepSeek之所以能在算力紧缺、人才流动的环境下敢于如此激进地调价,原因藏在那份58页的技术报告中。它早已不需要烧钱换市场。它是在用一套从头重构的底层架构,把大模型的推理成本推向了人们从未想象过的数量级。
读技术报告时,一个数字跳了出来:在百万token上下文场景下,V4的KV Cache占用仅仅是前代V3.2的10%。十分之一的定价,源头就在这里。
要讲清楚这件事,得从KV Cache说起。今天人们与大模型的对话远比几年前复杂,附上几十页的文档作为参考资料已经司空见惯。模型必须把这些冗长的内容记住,才能正确回答问题。这种记忆就是KV Cache。
问题在于,长篇大论带来的记忆既复杂又臃肿。一本百万字的书看起来轻薄,模型却需要占用十几张昂贵显卡的显存来保存记忆。实现长上下文窗口的成本,一直居高不下。
有人选择接受现实,DeepSeek选择了另一种路径:掀翻传统的记忆方式。
第一种新方法叫压缩稀疏注意力。传统注意力机制中,一个token对应一组KV向量。压缩稀疏注意力的做法是,通过可学习的线性投影和Softmax函数计算出压缩权重,将连续多个token的KV状态在序列维度上融合成一个单一条目。
翻译成直觉能理解的话:以前模型需要逐字逐句记住用户发来的内容,现在它学会段落总结,把每几十个词的核心意义浓缩成一句话。在V4 Pro中,压缩率设为4,仅这一步,缓存体积在序列长度上直接缩减75%。
第二种方法更加激进,叫重度压缩注意力。它试图把远大于常规压缩窗口的token记忆压进一个条目,不做稀疏检索,而是全局密集注意力计算。代价是计算开销增加,回报是压缩率惊人。在V4 Pro中,这一层的压缩率是128。段落总结还够,直接做篇章提炼,一整页内容浓缩成几个关键词。
但激进压缩必付代价。局部细粒度信息和严格的因果关系,都会被这种暴力压缩破坏。DeepSeek的解法是,在注意力机制中增加一个独立分支:窗口大小为128的滑动窗口。最近128个token不被压缩,以此保证模型对近期上下文的精确感知。缓存管理上,异构KV Cache架构将未压缩token作为一种状态独立管理,让高压缩比下的回答质量得以维持。
还有一步不能忽略:混合精度存储与磁盘复用。KV Cache中的特征维度,只有用于旋转位置编码的最后64维保留BF16精度,其余全部量化为FP8格式。物理存储又砍掉一半。
在这些层层削减之后,缓存体积已被压缩90%以上,因此V4可以将这些高度压缩的KV条目直接放到廉价的固态硬盘中。用户发起长文本请求时,系统从硬盘直接拉取已压缩的缓存,跳过了昂贵的GPU预填充计算,同时极大节省了HBM显存。
成本降到十分之一,顺理成章。
这是一种记忆的工业化。过去,记忆是手工作坊,每个细节都要原样保存。现在,记忆变成了流水线,有标准化工序、有压缩算法、有分级存储。冗余被剔除,本质被保留。
除了显存占用,推理计算时的浮点运算次数,是衡量算力消耗最主要的标准。在1M长上下文下,V4 Pro的单token推理FLOPs只有前代V3.2的27%。
下降的核心,是一套动态稀疏选择机制。即使有了压缩缓存,查询向量和前面几万个压缩后的KV向量计算注意力分数,计算量仍然庞大。DeepSeek的做法是:对于当前查询向量,模型通过下采样和上采样矩阵将其映射到低维隐空间,生成一个用于检索的索引Query向量。这个索引向量与历史缓存的压缩块计算粗略得分,每次生成token时只检索得分最高的1024个压缩KV条目,再进行后续的核心注意力计算。
传统注意力机制中,解码计算复杂度随上下文长度线性增长。压缩稀疏注意力将复杂度强制截断为常数级运算。当上下文长度达到一百万时,常数级的计算量几乎可以忽略不计。这是27%这个数字的结构性来源。
与此同步推进的,是精度的系统性妥协。V4不仅将混合专家架构的专家权重量化为FP4精度,还首次将FP4深入注意力计算的核心。Query和Key向量的激活值缓存、加载、矩阵乘法,全部在FP4精度下运行。量化感知训练期间,索引得分也从FP32降到BF16。硬件层面,FP4精度的吞吐量是FP8的两倍。这种极低精度计算让长上下文的注意力计算速度加倍,同时维持了99.7%的KV检索召回率。
99.7%的召回率值得品味。这意味着,算力下降了,精度几乎没有损失。过去人们本能地认为,更便宜意味着更差。DeepSeek用数据证明,这个等式不总是成立。在工程的世界里,冗余和裕度并不天然等于更好的结果。
自顶向下看完整套算法优化,再往下一层,是DeepSeek一贯的看家本领:对底层基础设施的彻底压榨。这种优化已经到了“抠门”的地步,却构成了集群吞吐量提升和降价护城河的真实来源。
V4 Pro参数量达到1.6万亿,在国内仅次于Kimi系列模型。但这也是问题所在。混合专家架构中,专家并行的跨节点通信,随着参数膨胀成为瓶颈。DeepSeek团队用自研的TileLang语言编写底层融合算子,将MoE层的计算按波次划分。一波专家的通信一旦完成,GPU立刻开始计算,网络层同时开始并行传输下一波专家的token。这种流水线式的重叠调度,将推理阶段的常规工作负载加速了1.50到1.73倍,硬件利用率逼近极限。均摊到每个请求上的算力折旧成本,被进一步压低。
还有一个针对智能体应用场景的独特优化。AI模型在执行复杂任务时,往往需要先运行一个额外的小模型进行意图识别或工具调用的判断。V4的解法更巧妙:在输入序列后附加专用的特殊token进行标记。由于模型原生支持多级思考和长短期记忆管理,可以直接复用主模型的KV Cache来并行执行这些辅助任务。额外模型的维护成本和重复预填充的计算开销,被一并消除。
这一步的意义,不是省了几台服务器。它指向一种哲学层面的分工:工具和意图之间的界限被模型内部化了。过去需要外部辅助系统完成的功能,现在被模型本身的结构所吸收。这是压缩,也是统一。
混合压缩注意力叠加硬盘低成本缓存,等于十分之一的缓存命中价格。稀疏注意力加上FP4精度再加上底层极致榨取,等于2.5折的推理价格。理解了这些技术,就能看明白这次突如其来的降价,本质不在慈善,也不在价格战。这是利用技术代差发动的降维打击。
说来有些讽刺。在国内AI市场涨价的主旋律中,行业在一个月内形成了心照不宣的默契:AI就该越来越贵。然后DeepSeek一言不发,让这种默契化为泡影。自研的千亿MoE架构、把单token成本打骨折的混合注意力机制,使得API价格降到对手不想、也不敢跟进的水平。
这已经不是同一个维度的竞争。
DeepSeek从未想过烧钱换市场,它背后是自研的整套推理框架,从底层算子到上层服务的全链路掌控。降价,只是因为成本真的降下来了。
而那些选择涨价的企业,无论是主动还是被动,无意中暴露了一个更残酷的事实:它们的技术栈和成本结构,根本不在自己手里。
这轮洗牌过后,大模型市场的定价权将发生转移。
过去,价格由“我能买到的最优模型成本”来定义。现在,价格由DeepSeek的自研模型成本来定义。当锚点已被砸到地板价,涨价的厂商会突然发现,手里的牌一张都打不出了。
百万级token上下文的廉价处理能力,让过去因成本悬置而无法落地的长文本分析、复杂Agent任务、横跨多轮的记忆与规划,都获得了经济可行性。这不是一个模型能力的突破,这是应用层即将大爆发的底层许可。
DeepSeek平台及时打消了外界传言“降价以应对竞争”的说法。“此次调整正是技术与规模效应形成正循环后,我们向市场自然传导成本优势。”这种表述,比任何反击都更有力。
回顾整件事,有一条更深的线索。
价格从来不只是数字,它是权力结构的物质外衣。当一个技术的定价权从供给方转移到效率方手中,它意味着旧格局开始瓦解。
20世纪初,福特用流水线把汽车价格从富人玩具打到工人阶层可承受的范围,背后的力量不是慈善,是生产效率的代际跃迁。今天DeepSeek把大模型API价格打到同行的十分之一,性质是一样的。谁掌握了最底层的效率,谁就掌握了定价权。谁掌握了定价权,谁就定义了下一个时代的基础设施。
硅谷有一种广为流传的叙事:AGI将在某个实验室被秘密诞生,然后单方面重塑世界。DeepSeek的实践提供了一种更安静的叙事:真正的权力转移,不需要一次惊艳的跑分或一篇石破天惊的论文。它只需要让技术报告里藏着一行小字,把成本打到所有人无法跟进的位置。然后用一个普通的周末,轻描淡写地把价格表更新。
Token终将变为水电一样的基础资源。这句话说了好几年,一直像愿景。直到这个周末,它突然变成了可以用0.025元买到的东西。
来源: 微信公众号“硅基星芒”,作者:思齐
-END-





 收藏
收藏









